GAIA Benchmark Agent
GAIA is a benchmark designed to be difficult for autonomous agents: each question is conceptually simple for a careful human, but demands multi-step reasoning, the right tool at the right moment, and tolerance for inputs that arrive as PDFs, spreadsheets, audio clips, images, or arbitrary web pages. I built this project as the Unit 4 capstone of Hugging Face’s AI Agents Course, a self-contained agent that ingests a GAIA task, decides what it needs, fetches files, reasons over them with the appropriate tools, and emits an answer in the exact string form GAIA’s grader expects.
The differentiators here compared to a typical ReAct loop agent are: 1) retrieval-augmented few-shot prompting, where our hybrid retriever fetches the most similar solved tasks and provides them as solved examples before the model reasons, and 2) separate formatter using a single tool, guaranteeing the exact-string match expected by the benchmark.
Architecture: a six-node LangGraph state machine
The agent is built on LangGraph, with each step modelled as a node and the conversation state passed between them as a typed dict. The graph is a plan → execute → observe → refine loop, with retrieval and answer-formatting that sets it apart.

- File Downloader Node: pulls any files associated with the current task from the GAIA API and caches them locally so downstream nodes can read them without network round-trips.
- Retriever Node: performs hybrid retrieval over a local corpus of 165 GAIA training questions. Supabase backs a dense vector store for semantic search, using
gte-modernbert-baseembeddings, whilebm25senables keyword search. The resulting lists from each search are merged with Reciprocal Rank Fusion. - Reranker Node: a ModernBERT cross-encoder re-scores the fused candidates, and the top-K survivors are injected into the processor’s prompt as few-shot examples of how to approach similar questions.
- Processor Node: the main solver. Calls Qwen3-32B via the Hugging Face Inference API, with the full tool catalogue bound. This node loops: think, pick a tool, observe its result, decide whether more work is needed. The recursion limit is configurable, so the agent doesn’t spin forever on adversarial tasks.
- Formatter Node: a second, deliberately constrained LLM call. It’s bound to exactly one tool,
emit_final_answer, which forces the model to emit its answer through a strict JSON schema rather than via free text.
Why Processor + Formatter nodes
GAIA grades answers via exact-string match. “Paris”, “paris”, and “The answer is Paris.” are three different things to the grader. A single LLM trying to both reason and respect the answer contract ends up failing the second task quite frequently. One solution to this problem is patching with regex post-processing, but that is fragile.
By splitting responsibilities, the processor reasons in whatever shape works best; chains of thought, partial calculations, tool-call traces, half-formed hypotheses. Then a dedicated formatter, with one specific task and bound to one tool only, ensures that the final answer is given into the exact format GAIA wants. The cost is one extra LLM call per task; the benefit is that the contract is now enforced by the tool schema.
@tool
def emit_final_answer(answer: str) -> str:
"""Emit the final answer to the GAIA question in the strict scoring format.
Args:
answer: The raw answer value only.
Numbers: plain digits, no commas, no units, no symbols (write '1000000', not '1,000,000' or '$50').
Strings: no articles ('a', 'an', 'the'), no markdown, no surrounding quotes, no trailing punctuation.
Lists: comma-separated with no extra spaces, in the order requested by the question.
"""
return answerWhy hybrid retrieval
Vector embeddings are used to find semantic neighbours: questions that aren’t worded the same but are about the same thing or concept. BM25 catches the literal-keyword cases, proper nouns, code identifiers and exact phrases. Vector-only retrieval fails to find useful context for “find the function compute_eigvals in this file”; BM25-only misses “what’s the boiling point of mercury” when the corpus uses different vocabulary. Fusing them with RRF gives you the best of both worlds, and the cross-encoder re-ranker is the final quality pass before the few-shot slot. The approach here might seem trivial when selecting such a small sample from each method and even smaller number out of the RRF, but what is important to showcase here is the concept, while we could scale each method to return dozens (hundreds if we had that many samples) of results and then combine and shortlist at subsequent steps. Note that we could have used the re-ranker to identify good candidates directly, without using the above retrieval methods, however that does not scale when dealing with thousands of documents.
Tools and modalities
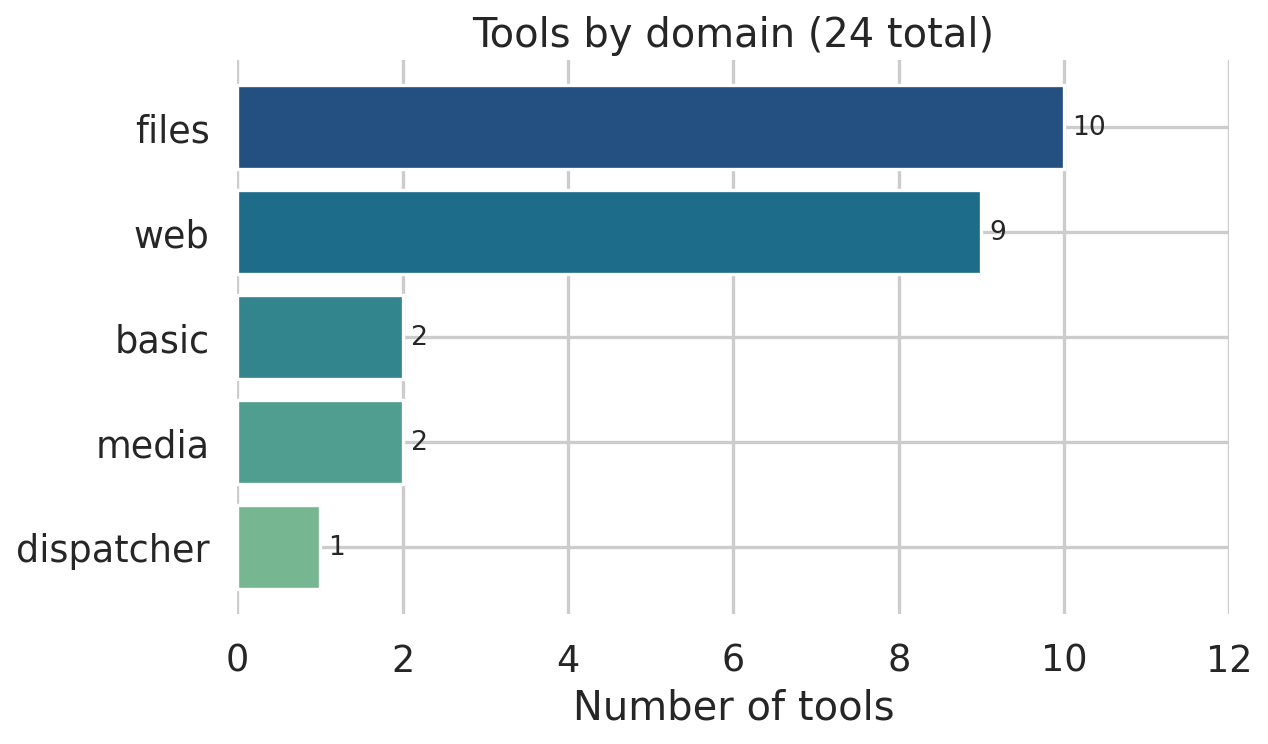
The agent reaches across every modality GAIA throws at it:
- Text & web: DuckDuckGo and Tavily for search, Wikipedia and arXiv for canonical sources,
trafilaturafor clean web-page extraction, the YouTube transcript API for video questions. - Files:
pypdffor PDFs,python-docx/python-pptx/openpyxlfor the Office stack,polarsfor tabular data,biopythonfor.pdbmolecular files, ZIP traversal for archives. - Media: Qwen3-VL-32B-Instruct as the vision-language model for image questions; Whisper-large-v3 for audio transcription.
- Compute: a sandboxed Python
evaltool and a calculator for basic arithmetic. - Dispatcher: instead of binding twenty file-specific tools to the LLM, a single dispatcher tool routes by file extension to the right handler. This keeps the visible tool list short, which keeps tool-calling reliable!
Tech stack
| Layer | Stack |
|---|---|
| Orchestration | LangGraph, LangChain |
| LLM / VLM / ASR | Hugging Face Inference API: Qwen3-32B, Qwen3-VL-32B-Instruct, Whisper-large-v3 |
| Retrieval | Supabase (vector store), sentence-transformers, bm25s, ModernBERT cross-encoder |
| Documents | pypdf, python-docx, python-pptx, openpyxl |
| Data / science | polars, biopython, pillow, librosa, soundfile |
| Web | ddgs, tavily-python, wikipedia, arxiv, trafilatura, youtube-transcript-api |
| UI | Gradio (provided by HF, minor edits) |
| Config | YAML: every model, retrieval depth, recursion limit and any other setting lives in config.yaml, not in the code |
Status on the Agents Course set
On the GAIA subset used by the Hugging Face Agents Course, the agent answers correctly every question that the scoring API will currently evaluate. In case you attempt to clone the repo, there are four questions containing files served via GET /files/{task_id}, which is presently returning 404 "No file path associated with task_id …" for every file-bearing task in the round (tracked in huggingface/agents-course#624). The agent handles the failure gracefully by calling retry_file_download once and then emitting FINAL ANSWER: unknown rather than hallucinate. Those four will be possible to evaluate again as soon as the API serves the underlying files.
Takeaways
A few honest notes from building this:
- Wikipedia related questions proved especially tricky, considering you had to look up articles as of specific dates and include information from navboxes on top of the main page content. Wikipedia itself was also silently refusing unidentified clients which had to be resolved.
- Run it against the full GAIA validation set. The Agents Course subset is a slice of the broader benchmark; attempting the full validation set is the obvious next step to see whether the architectural choices (two-stage formatter, hybrid retrieval, dispatcher) hold up at scale.
- Cost. The dual-LLM design (reasoning + formatter) increases token spend. For a benchmark, the reliability win is worth it; in production you’d want to A/B that decision against a single well-prompted call with structured output.
- The corpus is the ceiling. Retrieval quality is bounded by the 165 training-set questions. Expanding the corpus, even with synthetic examples, would compound the few-shot effect linearly with very little engineering work.
- The dispatcher pattern generalises. Routing-by-extension is a clean way to keep the agent’s visible tool count low even as the underlying file-format support grows. I’d reach for it again in any multi-modal agent.
Try it
- Repo: https://github.com/patelis/gaia
- Course: Hugging Face AI Agents Course — the capstone challenge that produced this project
- Keywords: LangGraph, LangChain, Qwen3, ModernBERT, Whisper, Supabase, BM25, RRF, Gradio